记录Lua源码解读过程中关键的知识点
虚拟机
Lua虚拟机工作流程:
- 将源代码翻译成虚拟机可以识别执行的字节码
- 为函数调用准备调用栈
- 内部维持一个PC(指令指针)来保存下一个将执行的指令地址。
- 模拟一个CPU的运行:循环拿出由PC指向的字节码,根据字节码格式进行解码,然后执行字节码
Lua是一个基于寄存器的虚拟机,操作数是放在寄存器中的,Lua中用一个大小为255的int数组来模拟寄存器。
源码中常见的结构体
以下代码全部基于Lua-5.4.3版本
-
函数原型Proto结构体
typedef struct Proto { CommonHeader; lu_byte numparams; /* number of fixed (named) parameters */ lu_byte is_vararg; lu_byte maxstacksize; /* number of registers needed by this function */ int sizeupvalues; /* size of 'upvalues' */ int sizek; /* size of 'k' */ int sizecode; int sizelineinfo; int sizep; /* size of 'p' */ int sizelocvars; int sizeabslineinfo; /* size of 'abslineinfo' */ int linedefined; /* debug information */ int lastlinedefined; /* debug information */ TValue *k; /* constants used by the function */ Instruction *code; /* opcodes */ struct Proto **p; /* functions defined inside the function */ Upvaldesc *upvalues; /* upvalue information */ ls_byte *lineinfo; /* information about source lines (debug information) */ AbsLineInfo *abslineinfo; /* idem */ LocVar *locvars; /* information about local variables (debug information) */ TString *source; /* used for debug information */ GCObject *gclist; } Proto;Proto结构体中主要有:
- 函数的常量数组
- 编译生成的字节码信息
- 函数的局部变量信息
- 保存upvalue名字的数组
-
虚拟机结构体
struct lua_State { CommonHeader; lu_byte status; lu_byte allowhook; unsigned short nci; /* number of items in 'ci' list */ StkId top; /* first free slot in the stack */ global_State *l_G; CallInfo *ci; /* call info for current function */ StkId stack_last; /* end of stack (last element + 1) */ StkId stack; /* stack base */ UpVal *openupval; /* list of open upvalues in this stack */ StkId tbclist; /* list of to-be-closed variables */ GCObject *gclist; struct lua_State *twups; /* list of threads with open upvalues */ struct lua_longjmp *errorJmp; /* current error recover point */ CallInfo base_ci; /* CallInfo for first level (C calling Lua) */ volatile lua_Hook hook; ptrdiff_t errfunc; /* current error handling function (stack index) */ l_uint32 nCcalls; /* number of nested (non-yieldable | C) calls */ int oldpc; /* last pc traced */ int basehookcount; int hookcount; volatile l_signalT hookmask; };每个Lua虚拟机对应一个
lua_State,结构体主要有:- stack:栈数组的起始位置
- base:当前函数栈的基地址
- top:当前栈的下一个可用位置
- ci:当前调用函数的信息
每一个lua_State类似于一个进程,可以同时创建多个Lua虚拟机对象,不同的Lua虚拟机之前的工作是线程安全的,因为一切和虚拟机相关的内存操作都被关联到虚拟机对象中。
luaL_newstate主要用来为每一个LUA线程创建独立的函数栈和线程栈,以及线程执行过程中需要用到的内存管理、字符串管理、gc等信息。
-
全局状态global_State
lua State 与 global State的关系
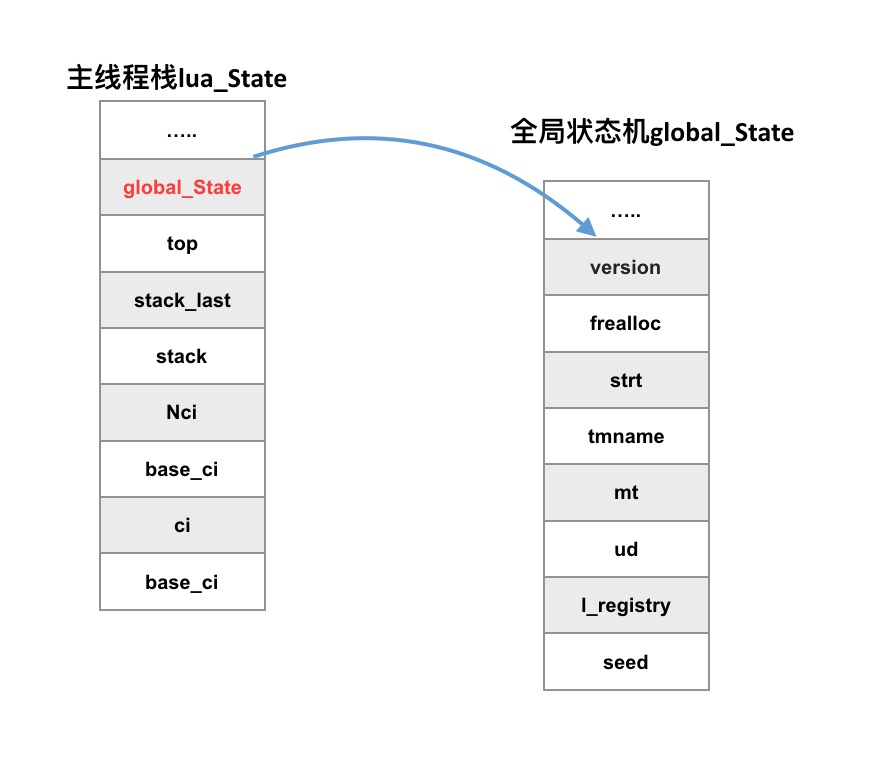
global_State 里面有对主线程的引用,有注册表管理所有全局数据,有全局字符串表,有内存管理函数,有GC 需要的把所有对象串联起来的相关信息,以及一切 lua 在工作时需要的工作内存。
同一Lua虚拟机中的所有执行线程,共享一块全局数据global_State。
源代码位于lstate.h,中,其中主要由以下几部分组成:
version:版本号panic: 全局错误处理stringtable:全局字符串表, 字符串池化,buff 在 字符串处理过程中的临时缓存区(编译过程中的parse也需要使用这块buff)。l_registry: 注册表(管理全局数据)seed:字符串 Hash 随机化Meta table:tmname (tag method name) 预定义了元方法名字数组;mt 每一个Lua 的基本数据类型都有一个元表。Thread Info:mainthread指向主线程(协程);twups 闭包了当前线程(协程)变量的其他线程列表。Memory Allocator:frealloc指向 Lua的全局内存分配器;ud 指向内存分配器的data。- GC 相关信息
-
CallInfo调用栈
typedef struct CallInfo { StkId func; /* function index in the stack */ StkId top; /* top for this function */ struct CallInfo *previous, *next; /* dynamic call link */ union { struct { /* only for Lua functions */ const Instruction *savedpc; volatile l_signalT trap; int nextraargs; /* # of extra arguments in vararg functions */ } l; struct { /* only for C functions */ lua_KFunction k; /* continuation in case of yields */ ptrdiff_t old_errfunc; lua_KContext ctx; /* context info. in case of yields */ } c; } u; union { int funcidx; /* called-function index */ int nyield; /* number of values yielded */ int nres; /* number of values returned */ struct { /* info about transferred values (for call/return hooks) */ unsigned short ftransfer; /* offset of first value transferred */ unsigned short ntransfer; /* number of values transferred */ } transferinfo; } u2; short nresults; /* expected number of results from this function */ unsigned short callstatus; } CallInfo;Lua中把调用栈和数据栈分开保存。CallInfo保存着正在调用的函数的运行状态。在CallInfo中,func指向正在执行的函数在数据栈上的位置。
-
线程(协程)
把数据栈和调用栈合起来就构成了Lua中的线程。它并非操作系统意义上的线程。Lua的程序运行是以线程为单位的。每条线程的执行互不干扰,可以独立延续之前中断的执行过程。在Lua中,协程的本质就是线程。当创建一个Lua状态时,Lua就会自动用这个状态创建一个主线程,并返回代表该线程的lua_State.
协程拥有自己的栈、局部变量和指令指针,同时协程又与其他协程共享了全局变量和其他几乎一切资源。在实现层面,多个协程在内部引用了相同的Lua状态。
-
进程
每次调用luaL_newstate都会创建一个新的Lua状态。不同的Lua状态之间是完全独立的,它们之间不共享数据。借助C语言代码,可以实现两个状态之间的通信,比如给定两个状态L1和L2,以下命令可以把L1栈顶的字符串压入L2的栈中:
lua_pushstring(L2, lua_tostring(L1, -1))在支持多线程的系统中,可以为每个线程创建一个独立的Lua状态。因为Lua状态之间只能交换C语言能够表示的类型,例如字符串和数值。其他诸如表之类的系统必须序列化后才能传递。
关于在多个lua state共享数据的一个实现可以参考这里:lproc
基础数据类型
通用数据结构
Lua通用数据结构的组织:
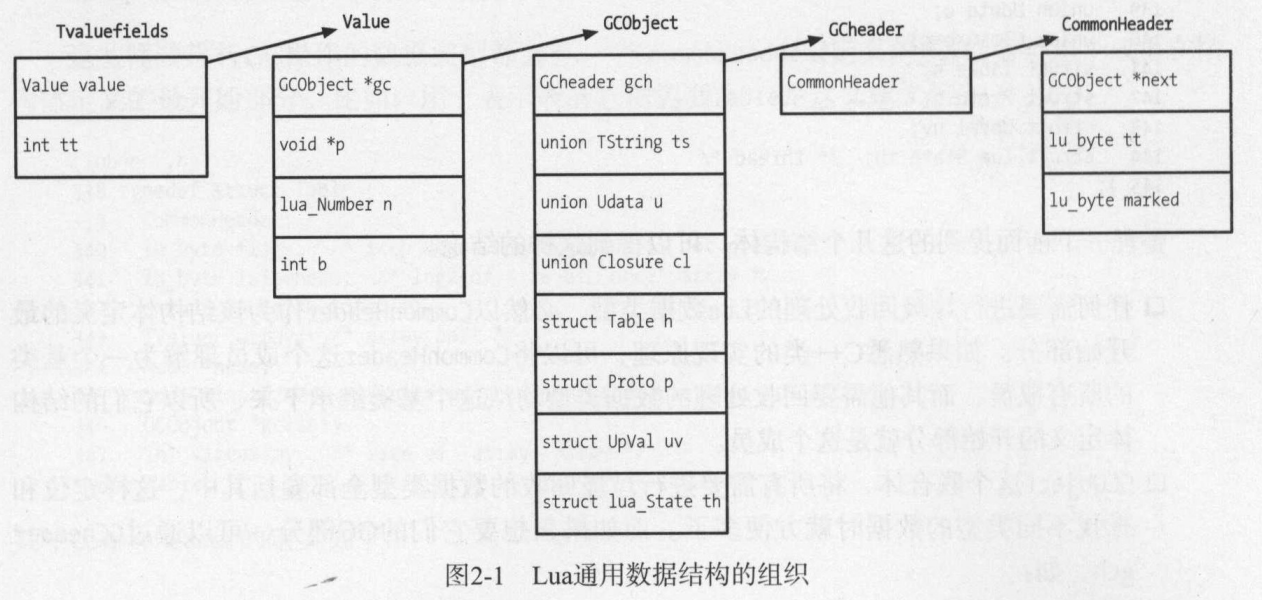
TValue作为统一表示所有数据的数据结构,内部使用了联合体Value将所有数据都包起来。
Lua中有两种userdata:LUA_TLIGHTUSERDATA 和 LUA_TUSERDATA ,对应的都是void* 指针,区别在于前者的分配释放由Lua外部的使用者去完成,而后者则是通过Lua内部来完成的。
字符串
在Lua中,字符串实际上是被内化的一种数据。简单来说,每个存放Lua字符串的变量,实际上存放的并不是一份字符串的数据副本,而是这份字符串的引用。
所以,每当创建一个字符串时,都会经过以下步骤:
- 首先都会取检查当前系统中是否已经有一份相同的字符串数据了,这个步骤是通过hash比较来完成的
- 如果存在直接将引用指向已存在的字符串数据
- 否则就重新创建出一份新的字符串数据
Lua虚拟机使用散列桶来管理字符串。在global_state里,strt成员负责存储当前系统中的所有字符串,strt是一个散列数组。在创建字符串时,如果此时字符串的数量大于桶数组的数量,且桶数组的数量小于MAX_INT/2,那么散列桶会进行翻倍的扩容。
注意:在Lua中,每次字符串连接符 .. 都会产生一个字符串,所以对于不需要中间结果的字符串,应该使用table.concat进行字符串连接
表
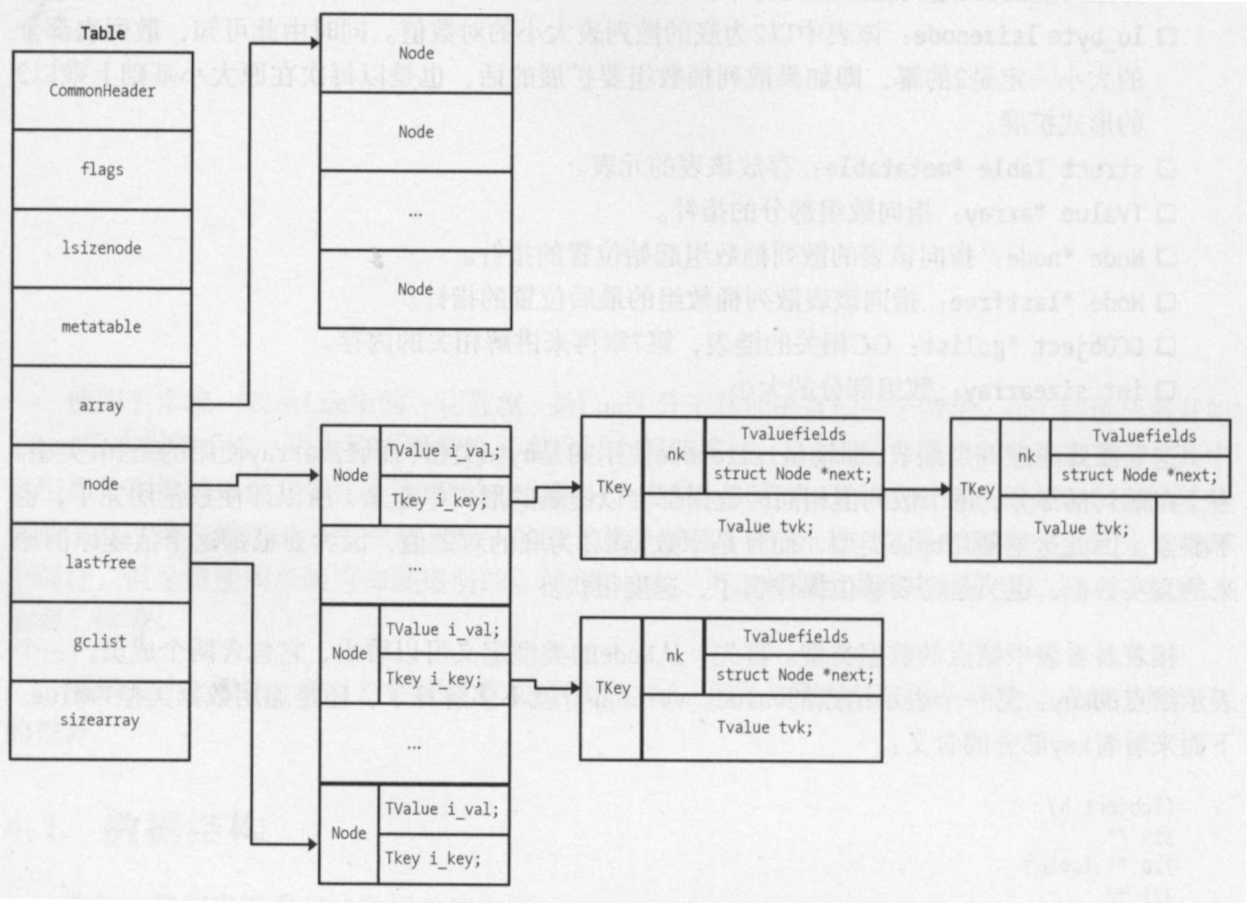
Lua表的实现分为数组和散列表部分。
typedef struct Table {
CommonHeader;
lu_byte flags; /* 1<<p means tagmethod(p) is not present */
lu_byte lsizenode; /* log2 of size of 'node' array */
unsigned int alimit; /* "limit" of 'array' array */
TValue *array; /* array part */
Node *node;
Node *lastfree; /* any free position is before this position */
struct Table *metatable;
GCObject *gclist;
} Table;
array:指向数组部分的指针node:指向该表的散列桶数组起始位置的指针flag:一个位标记,用于表示该表提供了哪些元方法
查找表元素伪代码:
if (key is int) && (0 < key < sizeof(array))
在数组部分查找
else 尝试在散列表部分查找:
计算出key的hash值,根据hash值访问Node数组得到散列桶所在的位置
遍历该散列桶下的所有链表元素,直到找到该key为止
新增表元素:
添加表元素的流程比较复杂,因为涉及重新分配表中数组和散列表部分的流程。代码逻辑位于ltable.c的newkey方法中。
newkey 方法定义:
void luaH_newkey (lua_State *L, Table *t, const TValue *key, TValue *value)
方法的操作流程:
- 根据key来查找其所在的散列桶的mainposition,mainposition表示计算数据的key所在的桶数组位置。如果返回的Node的值为nil,那么直接将key赋值并且返回Node的TValue指针。
- 否则说明该mainposition上已经有其他数据了,需要重新分配空间给这个新的key,然后将这个新的Node串联到对用的散列桶上。
可见整个过程都是在散列桶部分进行的,因为即使key是一个数字,也已经在调用newkey函数之前进行了查找,结果却没有找到。所以这个key都会进入散列桶部分来查找
如果找不到合适的位置来存放新的key,就会触发对表空间重新分配的情况,入口函数时rehash。
/*
** nums[i] = number of keys 'k' where 2^(i - 1) < k <= 2^i
*/
static void rehash (lua_State *L, Table *t, const TValue *ek) {
unsigned int asize; /* optimal size for array part */
unsigned int na; /* number of keys in the array part */
unsigned int nums[MAXABITS + 1];
int i;
int totaluse;
for (i = 0; i <= MAXABITS; i++) nums[i] = 0; /* reset counts */
setlimittosize(t);
na = numusearray(t, nums); /* count keys in array part */
totaluse = na; /* all those keys are integer keys */
totaluse += numusehash(t, nums, &na); /* count keys in hash part */
/* count extra key */
if (ttisinteger(ek))
na += countint(ivalue(ek), nums);
totaluse++;
/* compute new size for array part */
asize = computesizes(nums, &na);
/* resize the table to new computed sizes */
luaH_resize(L, t, asize, totaluse - na);
}
rehash主要操作有:
- 分配一个位图nums,将其中的所有位置0。nums数组中第i个元素存放的时key在和之间的元素数量
- 遍历Lua表的数组部分,计算其中的元素数量,更新对应的nums数组中的元素数量(numusearray函数)
- 遍历Lua表中的散列桶部分,因为其中也可能存放了正整数,需要根据这里的正整数数量更新对用的nums数组元素数量(numusehash函数)
- 此时nums数组已经有了当前这个Table中所有正整数的分配统计,逐个遍历nums数组,获得其范围区间内所包含的整数数量大于50%的最大索引,作为重新散列之后的数组大小,超过这个范围的正整数,就分配到散列桶部分(computesizes函数)
- 根据上面计算得到的调整后的数组和散列桶大小调整表(resize函数)
Lua的标准就是希望数组在每一个2次方位置容纳的元素数量都超过该范围的50%。
考虑以下代码:
local a = {}
for i=1,3 do
a[i] = true
end
根据以上算法我们发现这段代码会执行三次重新散列操作,所以如果需要创建很多很小的表,可以预先填充避免重新散列操作。比如 a = {true, true, true},Lua就会直接创建含有3个元素的数组。
Lua表优化相关技巧:
- 尽量不要将一个表混用数组和散列桶部分。
- 尽量避免重新散列操作,因为重新散列操作的代价极大。
取表长度算法:
如果表存在数组部分:
在数组部分二分查找返回位置i,其中i是满足条件t[i] ~= nil and t[i + 1] == nil 的最大数据
否则前面的数组部分查不到满足条件的数据,进入散列表部分查找:
在散列桶部分二分查找返回位置i,其中i是满足条件t[i] ~= nil and t[i + 1] == nil 的最大数据
环境与模块
环境相关的变量
- Global表存放在lua_State结构体中,也成为_G表。每个lua_State结构体中都有一个对应的_G表,负责存放全局变量。
- ENV表存放在Closure结构体中,每个函数有自己独立的一个环境
- registry表是全局唯一的,它存放在global_State结构体中。这个表只能由C代码访问。
- UpValue用于提供函数内静态变量的存储。
模块加载
在Lua内部,所有模块的注册都在linit.c的函数luaL_openlibs中提供。这个函数完成了Lua中基本模块的初始化,例如package、table、io、os、string等库。
- 创建模块时会创建一个表,该表挂载在registry["_LOADED"]、_G[module name]下。自然而然地,该模块中地变量(函数也是一种变量)就会挂载到这个表里面。
- 在module函数地参数中写下package.seeall将会创建该表地metatable,同时该表地__index将指向_G表。简单地说,这个模块将可以看到所有全局环境下地变量
require函数对应loadlib.c中地ll_require函数,所做的工作包括:
- 在registry["_LOADED"]表中查找该库,如果已存在,说明是已经加载过地模块,不再重复加载直接返回
- 在当前环境中查找loaders变量,这里存放地是所有加载器组成地数组。加载时,会依次调用loaders数组中的四种loader。如果加载的结果在Lua栈中返回的是函数(Lua源代码文件解析完,返回的是Closure),那么说明加载成功,不再继续往下调用其他的loader加载模块
- 最后,调用lua_call函数尝试加载该模块。registry["_LOADED"]返回true表示加载成功。
Lua语言编译器将代码中的所有自由名称x转换为_ENV.x。自由名称表示没有关联显式声明上的名称。对于以下代码:
local z = 10
x = y + z
Lua编译器会编译为:
local _ENV = *the global environment
return function (...)
local z = 10
_ENV.x = _ENV.y + z
end*
所有的变量要么是绑定到一个名称的局部变量,要么是_ENV的一个字段。
Lua处理全局变量的方式:
- 在编译所有代码段前,在外层创建局部变量_ENV;
- 编译器将所有的自由名称var变换为_ENV.var
- 函数load或loadfile使用全局环境初始化代码段的第一个upvalue,即Lua语言内部维护的一个普通的表。
通常_G和_ENV指向的都是同一个表。_ENV是一个局部变量,所有对“全局变量”的访问实际上访问的都是_ENV,_G是一个在任何情况下都没有任何特殊状态的全局变量。_ENV永远指向当前的环境;_G通常指向全局环境。
如果定义一个名为_ENV的局部变量,那么对自由名称的引用(在局部范围内)会绑定到这个新变量上。
load通常把被加载代码段的upvalue _ENV初始化为全局环境。不过load有一个可选参数让我们为_ENV指定一个不同的初始值。
模块热更新原理
如果要实现Lua的代码热更新,其实也就是需要重新加载某个模块,因此想办法让Lua虚拟机认为它之前没有加载过就行。查看Lua代码就能发现registry["_LOADED"]表实际上对应的是package.loaded表,所以只需要在require模块之前执行以下操作就行:
package.loaded[module name] = nil
但是需要注意,这样会重新加载整个模块,所以要想恢复之前的环境,需要保存之前的执行环境。在Lua中可以认为只有Closure,Closure是函数原型Proto和UpValue的结合体。通过debug.getupvalue(func, i) 能够取到func函数的所有upvalue,对应的debug.setupvalue能够设置func函数的upvalue。
与C语言交互
- Lua标准库中没有定义任何C语言全局变量,它将其所有的状态都保存在动态的结构lua_State中。
- Lua和C之间通信的主要组件是通过一个虚拟栈来完成的。栈中的每个元素都能保存Lua中任意类型的值。由于这个栈是Lua的一部分,因此垃圾收集器知道C语言正在使用哪些值。
- C API 使用索引来引用栈中的元素。第一个入栈的元素索引为1,后续进栈元素递增。也可以使用负数索引来访问栈中元素:-1表示栈顶元素。
Lua调用C语言
- Lua调用C函数时,也是通过栈来交换数据,但是这个栈不是全局结构,每个函数都有其私有的局部栈。
- 所有在Lua中注册的函数都必须使用一个相同的原型:
typedef int (*lua_CFunction) (lua_State *L) - Lua通过注册过程感知到C函数。一旦一个C函数用Lua表示和存储,Lua就会通过对其地址(注册函数时提供给Lua的信息)的直接引用来调用它。
C语言调用Lua
▢ TODO
垃圾回收
垃圾回收原理
▢ TODO
垃圾回收要点
-
弱引用表(weak table)允许收集Lua语言中还可以被程序访问的对象
-
一个表是否为弱引用表由其元表中的__mode字段所决定的。
a = {} -- k 代表a的键是弱引用的 -- v 代表a的值是弱引用的 -- v 代表a的键和值都是弱引用的 mt = {__mode = "k"} setmetatable(a, mt) -
只有对象可以从弱引用表中被移除,而像数字和布尔、字符串这样的“值”是不可回收的。
-
弱类型表只要键或者值被回收,对应的整个键值都会被从表中删除
-
-
析构器(finilizer)允许收集不在垃圾收集器直接控制下的外部对象
- 析构器是一个与对象关联的函数,当该对象即将被回收时会被调用
- Lua语言通过元方法__gc实现析构器
-
collectgarbage允许我们控制收集器的步长
-
Lua垃圾回收周期:
- 标记: 把根节点集合标记为活跃,根节点集合由Lua语言可以直接访问的对象组成。在Lua语言中,这个集合只包括C注册表。保存在一个活跃对象中的对象也会被标记为活跃(弱引用除外)。
- 清理: 处理析构器(把析构对象放到一个单独的表中以供后续使用)和弱引用表。
- 清除: 遍历所有对象(Lua把所有创建的对象放在一个链表中),回收没有被标记为活跃的对象,清理剩余对象的标记。
- 析构: 调用清理阶段被分离出的对象的析构器
参考
- Lua源码分析 - 基础篇 - 全局状态机的实现
- 《Lua程序设计》 Roberto Ierusalimschy
- 《Lua设计与实现》 codedump
- 《Lua源码剖析》 云风